In the last couple of months, I got more and more interested in learning, especially reading. Loving tech and sports, I got easily hooked on the Quantified Self movement (I own a Zeo Sleeping Coach and several step counters). Seeing how measuring myself transformed me. I lost around 4 kg and feel healthier/fitter, since I started tracking. I wonder why we don’t have similar tools for our learning behavior.
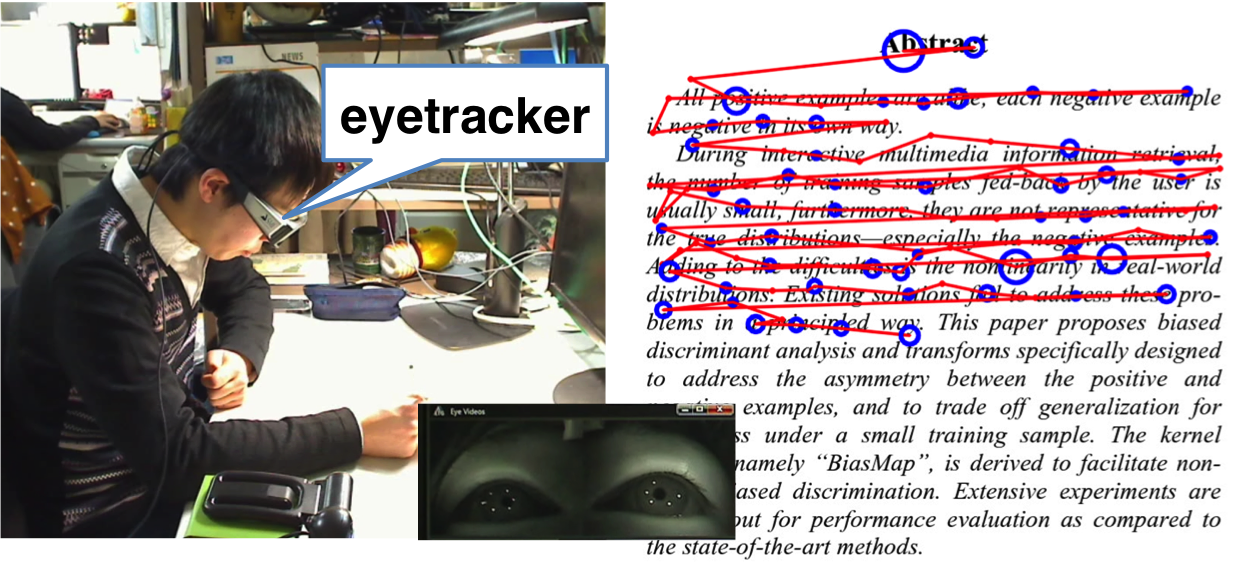
So we created a simple Wordometer in our Lab, using the SMI mobile eyetracker and document image retrieval (LLAH). We simply detect reading (very distinct horizontal or vertical movements) and afterwards count line breaks. Assuming a fixed number of words per line, voilà here is your Wordometer. The document image retreival is used to keep the accuracy at around 5-7 % (comparable to the pedometers measuring your steps each day).
Of course, there are a couple of limitations:
- Mobile Eyetrackers are DAMN expensive. Yet, the main reason being that there is no demand and they are manufactured in relatively low numbers. A glass frame, 2 cameras and 2 infra-red sources that’s it (together with a bit of image processing magic).
- Document Image Retrieval means you need to register all documents with a server before reading them. I won’t go into details as this limitation is the easiest to get rid of. We are currently working on a method without it. At the beginning it was easier to include (and improve the accuracy rate).
- Not everybody likes to wear glasses. With the recent mixed reception of Google Glass, it seems that wearing glasses is way more a fashion statement than wearing a big “smart” phone or similar. So this tech might not be for everybody.
Overall, I’m still very exited on what a cheap, public avaiable Wordometer will do to the reading habits of people and their “knowledge life”. We’ll continue working on it ;)
We are also using eyetracking, EEG and other sensors to get more information about what/how a user is reading. Interestingly, it seems using the Emotiv EEG we can detect reading versus not reading and even some document types (manga versus textbook).
Disclaimer: This work would not be possible without two very talented students: Hitoshi Kawaichi and Kazuyo Yoshimura. Thanks for the hard work :D
For more details, check out the papers:
- The Wordometer – Estimating the Number of Words Read Using Document Image Retrieval and Mobile Eye Tracking
- Reading Activity Recognition using an off-the-shelf EEG — Detecting Reading Activities and Distinguishing Genres of Documents
They are both published at ICDAR 2013.